
This is a high-level writeup for my research sprint for Neel Nanda’s SERI MATS 2023 Summer application.
You can find the colab notebook that I coded in here and my mini research log here. The former details my reasoning, thinking, and surprise over time; the latter, while it doesn’t offer any significantly novel information that this writeup doesn’t, also highlights some related things I was learning.
Project Focus
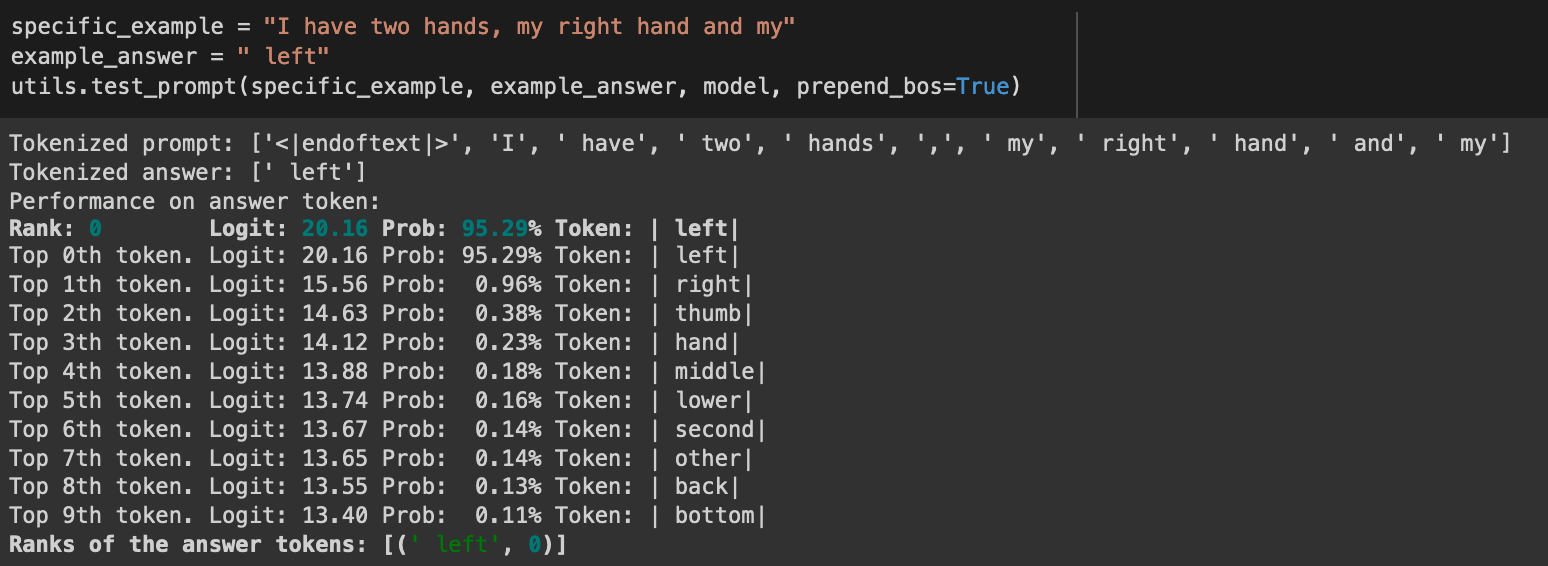
I set out to find and explore any sort of behavior achievable by GPT-2 Small1. After an extensive amount of iteration, I stumbled across a certain style of prompt that it was very good at completing; in essense, GPT-2 small was really good at predicting words when it knew it was going to be the “opposite” of another word.
For instance, GPT-2 completes the prompt I have two hands, my right hand and my with left. It also does this with really high confidence, as well. This makes sense, as the words “left” and “right” often come in pairs - and so if the word "right" shows up, it makes sense that the model would predict "left" if its looking for another adjective.
However, this extends beyond just left/right - there were other pairs of words that GPT-2 maintained this property for, such as me/you or up/down.
I’ll call this duality - given a word with a ‘dual opposite’, GPT-2 small is pretty darn good at predicting the dual opposite when necessary, even when it’s not previously present in the previous tokens.
I thought this would be an exciting project focus cause I predcited that whatever circuit was involved with this would involve a significant use of MLPs, and I wished to learn more about how attention layers and MLP layers interact!
Analysis
I must admit that at times, I didn’t have strong intuitions about how to go about this sort of analysis. Many times I just went “okay let me try this technique that Neel has in this one notebook.”" However, there was some thinking behind my deciscions, and I’ll try to give a quick overview here.
I predicted that discovering a circuit behind duality would be way too general, so I tried to focus on a circuit behind left/right duality first. This seems to have been a good guess, because left/right duality may have been too general in the first place as well!
The left (orange) line looks nice and smooth, but as I broke down all the prmopts individually on the right, things became much more messy. Prompts where GPT-2 small needs to predict “left” as opposed to prompts where it needs to predict “right” progress in qualitatively different ways. As such, I narrowed my focus further to simply focus on ’left-correct’ prompts: prompts which required GPT-2 to predict ’left’ as the correct answer.
[!Note] On the asymmetry of the
right/leftduality:This may, at first, feel unintuivive because right and left should both essentially be equivalent. It felt intuitive to me first as well.. But, after exploring this further, I realized that
righthas the unfortunate property of being a dual with another word,wrong!
From now on, it’s safe to assume that for all of our tasks, the “correct” token should be left.
The next natural step to understanding the circuit seemed to be to look at the direct logit attribution of all the heads. Surprisingly, only one head provides a significant logit difference!
We can see that Layer 9, Head 7 likely plays a significant role in the circuit for completing left-correct prompts. And looking at the actual attention patterns of the head, it reinforces the idea; it allocates almost all of its attention towards the information stored in the right token.
While I initially naively interpreted this as “oh okay so we only have one important attention head, nice,” I forgot that that this only reflected on which heads actually wrote to the subspace-which-mapped-later-to-the left-token. Importantly, there could - and were - attention layers which seemed to be a part of the circuit, but whose work didn’t reflect in the residual stream until later.
This becomes apparent when you start performing Activation Patching on the residual stream at both resid_pre (the residual stream before an Attention Layer) and resid_mid (the residual stream before an MLP layer). Here, I iteratively patched in multiple locations of the transformer, and measured the dual_metric performance 2 - the higher the number, the more the model ended up guessing left as opposed to right when patching at that location.
Specifically, above, we notice that when we patch in:
- the 7th (
'left') token- layer 6, resid_pre: recovers most performance
- layer 6, resid_mid: recovers some performance
- the last (
'my') token:- layer 6, resid_pre: recovers almost no performance
- layer 6, resid_mid: recovers some performance
This indicates that the attention layer 6 is doing something thats relevant, but not immediately manifesting itself in the “logit subspace.” When is this information being used? Graphing out how the logit difference changes throughout the residual stream while controlling for when we patch into the last token shows us this.
This is a busy and messy graph, apologies in advance.
But back to the question at hand of where attention layer 6’s work is being manifested in - look at the mid 6 line, representing when we patch in resid_mid 6 of the last token. We can see that the information doesn’t get ‘written to the logit subspace’ until 9_pre, where the logit difference jumps to almost 0.5. This is evidence that the 8th MLP layer is acting on whatever is being written to the last token’s residual stream in the 6th attention layer. How strong of evidence? I’m not sure. Certainly not enough to where I’m vastly confident, but it’s a good starting point 3!
This graph also gave many, many other observations that I felt were critical (you can look at the research log under May 5th for more detail). Some highlights:
- Attention Layer 8 also seems to be another important attention layer of the circuit
- You can get this from seeing how much performance improves when you patch at
resid_mid 8 - Heads 1, 6, and 8 seem important
- You can get this from seeing how much performance improves when you patch at
- Whateverever information that the attention layers up till MLP 8 provide are getting written into the ’logit subspace’ in MLP 10.
Beyond these graphs, there are other observations I gathered that I felt were important:
- The head responsible for the work of attention layer 6 is head 1.
- There are some parallels between the circuit for completing left-correct prompts and the circuit completing right-correct prompts. For instance, attention head 7 in layer 9 is also writes the most to the logit subspace for right-correct prompts, too.
- The presence of the token for the body part, or the token
two, both don’t seem highly important - This circuit seems to partially generalize to other, completely different, dual pairs as well! For instance, head 7 layer 9 is continually important, the same heads in layer 8 attend to the dual tokens, and layer 6 is where the circut seems to start.
My Best Hypotheses for the Circuit
So, I currently have an assortion of evidence, coupled with a lot of questions. Throughout this process, my best guesses for the circuit have changed multiple times, and it would be naive to predict that my current guess is super accurate. While I don’t have a good high-level idea of how the circuit completely adds up, I have some loose ends.
As such, here are some of my predictions and hypothesis about left-correct or duality-holding prompts, along with my credences in them. (All of these probabilities are conditioned upon the probablistic statements above them holding true. These are loose intuitions, so perhaps a $\pm$ 30% variance is in order 😅) More reasoning for some of these predictions can be found under May 5th in the research log - I just wanted to aggregate these here.
- There is a generalizable circuit for detecting, and completing, the word “left” when it sees the word “right” appear (90%)
- If a circuit gets flushed out for these kind of promts, Attention Head 9.7 (layer 9, head 7) will play a significant role (90%)
- because it:
- moves information about
leftitself to the last token (70%) - takes both the information about the presence of the
lefttoken, as well as information about “two” and/or “hand” that has accumulated within it, and moves it into the final token, which helps indicate duality (30%)
- moves information about
- Attention Head 9.7 writes information which is usefully processed:
- by MLP layer 104 (75%)
- Attention head 9.7 acts as the ‘duality detector’ and looks for words with common pairs (35%).
- by other MLP layers (30%)
- by nothing else, it in of itself provides the logit increase and thats it (10%)
- by MLP layer 104 (75%)
- because it:
- If a circuit gets flushed out for these kind of promts, Attention Head 6.1 will play a significant role (75%)
- The information being written to the residual stream of the last token because of this head is designed to be meaningfully processed5 in a later MLP (90%)
- Attention head 6.1 acts as the ‘duality detector’ and looks for words with common pairs (35%)
- If a circuit gets flushed out for these kind of promts, any one of Attention Heads 8.1, 8.6, or 8.8 will play a significant role (75%)
- All of them play some sort of role (30%)
- The information being written to the residual stream of the last token because of these heads is designed to be meaningfully processed in a later MLP (80%)
- If a circuit gets flushed out for these kind of promts, no part of it will lie in Transformer layers 1-5 (60%)
- If a circuit gets flushed out for these kind of promts, MLP layer 10 will have some sort of mechanism for reading the residual stream for the presence of dual words, and then writing the dual opposite to the residual stream (50%)
- Same as above, but for MLP 8 (50%)
- There is a huge component to this circuit that I haven’t discovered (80%)
- If a circuit gets flushed out for these kind of promts, Attention Head 9.7 (layer 9, head 7) will play a significant role (90%)
- There is a generalizable circuit for detecting, and completing, dual pairs of words (70%)
- The circuit for left-correct prompts will be intensely related to (like, a subset of) the circuit for completing prompts with dual pairs (65%)
- If a circuit gets flushed out for these kind of prompts, Attention Head 9.7 is important (70%)
You can find the colab notebook that I coded in here and my mini research log here. The former is good if you want to look at the code I did and follow my general thinking over time; the latter, while it doesn’t offer any significantly novel information that this writeup doesn’t, offers insight into what I was learning during the project, and how my perceptions changed over time.
Wanted to work with a small model as per Neel’s advice that bigger models are a nightmare. GPT-2 small “only” has 12 layers and heads, totaling for 85 million parameters ↩︎
You can look at the code for more details, but in short, this is a proxy of how much performance is recovered when running the model on an incorrect prompt and then ‘patching’ at a location with the correct version of the residual stream. ↩︎
As one, immediately obvious, counterpoint to this being evidence: all of the lines jump as a result of MLP 8 (just a bit less)! ↩︎
Doesn’t have to be exclusively MLP 10 ↩︎
I realize “meaningfully processed” is a bit fuzzy, but I’m imagining that some MLP is checking for this information and then writing to the logit subspace as a result of the written information ↩︎